Real-Time Ingestion: Keeping Vespa Tensors Fresh Without Killing Your Database
In my previous deep-dives into Vespa Streaming Mode and Multi-Stage Hybrid Ranking, we looked at how to optimize query speeds and ranking performance natively within Vespa. But there is a silent pipeline killer that architects rarely talk about until production breaks: Data Freshness.
Imagine an e-commerce platform or a hyper-local engine where prices, descriptions, or availability metrics update hundreds of times a minute. If your search engine relies on a nightly batch job to re-index documents, your users are searching across stale data.
However, if you try to fix this by generating vector embeddings synchronously during the database write cycle, you will create a severe performance bottleneck. Let's look at how to build an asynchronous, event-driven pipeline that keeps your Vespa tensors perfectly fresh without adding overhead to your transactional database.
The Synchronous Trap: Why Inline Vector Generation Fails at Scale
When a user updates a record, it’s tempting to throw that text at an embedding model API, wait for the vector array, and update both your primary database and Vespa in a single controller method.
Here is why that architecture breaks down under load:
- Network Latency: External embedding APIs (like Gemini or OpenAI) can take anywhere from 100ms to over 1 second to return a tensor array. Forcing your primary transactional database to hold a connection open while waiting for an external API call will rapidly deplete your database pool.
- Blast Radius: If the embedding provider goes down or encounters rate-limiting (HTTP 429), your primary application writes will fail or back up, taking your core user experience down with it.
To solve this, a Senior Solution Architect will always separate the transactional state from the downstream search indexing layer.
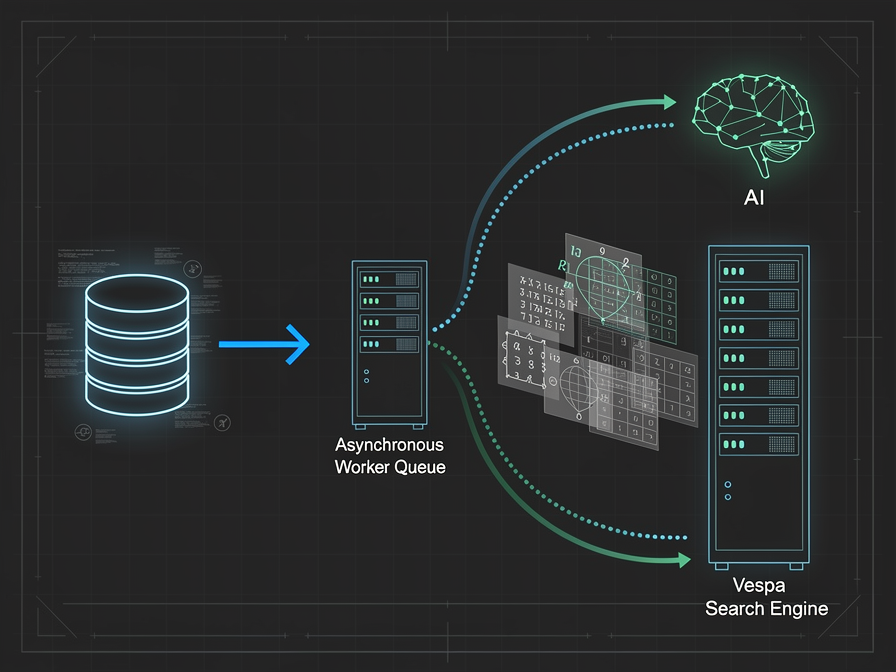
The Decoupled Blueprint: Event-Driven Tensor Synchronization
Instead of updating Vespa inline, we emit a lean event to a high-throughput message broker or a reliable queue mechanism immediately after the database write succeeds. This ensures the user's web request completes in single-digit milliseconds.
Step 1: Capturing the Database Event Safely
Your primary database should focus entirely on data persistence. For example, when using a modern backend application stack, you can hook into model lifecycle events to dispatch a background job without blocking the thread.
PHP
// Dispatching a lightweight background job immediately upon database commit
public function saved(Product $product)
{
// Pass only the identifier to keep the event payload clean
SyncProductToVespa::dispatch($product->id);
}
By passing only the model identifier, you minimize memory consumption within your message broker.
Step 2: The Worker Layer—Asynchronous Embedding Generation
The background worker is where the heavy lifting occurs. This process operates independently from the user-facing application, allowing it to absorb spikes in volume gracefully.
The worker retrieves the fresh data from the database, sends the text to the embedding provider, and prepares the payload for Vespa.
PHP
public function handle()
{
$product = Product::find($this->productId);
// Generate the multi-dimensional vector array asynchronously
$embedding = Ai::embeddings()->create(
text: "{$product->title} {$product->description}"
);
$this->updateVespaCluster($product, $embedding);
}
Step 3: Pushing Real-Time Document Updates to Vespa
Vespa provides a highly optimized HTTP/2 Document API designed for concurrent, real-time feed operations. Instead of pushing a massive, heavy payload, we can use a partial document update to modify only the specific fields and tensor attributes that changed.
HTTP
# Partial document update request sent to the Vespa Document API
PUT /document/v1/namespace/product_doc/docid/prod_99482
{
"fields": {
"title": { "assign": "High-Performance Running Shoes" },
"embedding": { "assign": [0.012, -0.043, 0.891, ...] }
}
}
Because Vespa handles partial updates efficiently at the storage node layer, this operation resolves instantly, ensuring your search indexes stay structurally fresh.
Dealing with Backpressure: Safeguarding the Ingestion Pipeline
When designing high-throughput data pipelines, you must plan for peak traffic conditions (e.g., massive catalog imports). If your system attempts to process 100,000 updates simultaneously, you will likely hit API rate limits or saturate your server's network bandwidth.
To mitigate this, implement a rate-limiting bucket strategy on your background workers. If an embedding provider returns a rate-limit alert, configure your ingestion workers to release the job back into the queue with an exponential backoff strategy. This ensures your search engine catches up automatically once traffic stabilizes, without dropping a single document update.
FAQ: Frequently Asked Questions on Vespa Ingestion Architecture
Q: How fast does data become searchable in Vespa when using this approach? When decoupled correctly via background workers, the typical end-to-end latency from database write to Vespa availability is usually sub-second (typically between 200ms to 500ms). This safely satisfies real-time data freshness requirements for almost all enterprise applications.
Q: Can I skip the embedding API for text updates that don't alter semantic meaning? Yes. As an architectural optimization, you can compare the original text with the updated text before dispatching your job. If only structural fields like metadata or pricing changed, you can bypass the embedding generation entirely and issue a partial update containing only those specific fields to Vespa.
Related Articles

Discussion
Leave a comment
Comments are moderated before appearing.
No comments yet — be the first to share your thoughts.